

Recently I got to hear more about Transport for London’s cycle superhighway modelling. TfL are rightly proud of their modelling work and I’m particularly pleased about their recent focus on cycling, traditionally so poorly dealt with in transport models.
But I’m concerned at how the modelling techniques have been used and the impact this has had on debates over the superhighways. And sure, some of this is the press, or the lobbyists. But that’s entirely predictable. We know that in high-profile, controversial areas, a number in a model (one result of a combination of often challengeable assumptions about human behaviour) is likely to be seized on as equating to a certain real world outcome. So we need to talk about how modelling works – or doesn’t – for good, evidence-based policy.

Superhighway plans, Tower Hill
Let’s take the case of the extra sixteen minute delays forecast for motorists driving from Limehouse Link Tunnel to Hyde Park. This prediction’s due to signal re-timing in East London, which aims to maintain motor traffic flow along Embankment when the East-West Superhighway goes in. A similar figure pops up in the North-South modelling results. We then see Matthew Beard, in the Evening Standard, writing (note the ‘will increase’):
Some of that’s spin, of course. Some car journeys are predicted to get quicker. However, the TfL modellers are keen to stress that all the figures are a ‘worst case’, showing the worst possible impacts on journeys made during the busiest peak hour.
And we should focus on planning for worst cases, right?
Well no, not necessarily. Sometimes, but not always. Some worst cases are downright implausible but can still happen. I’ve had a project suffer thanks to a key official dataset being withdrawn due to fraud allegations. So, would it be a good idea for other researchers planning to use official data to explain what they would do if this happened? Probably not. (They certainly never do!)
In the academic modelling I’m familiar with, you don’t use a single ‘worst case’ figure to present results. It’s more usual to give estimates based on the most likely case, ideally with a range of uncertainty, saying what the range is 95% of the time. Often the model is run many times with different plausible values for many of the inputs, and the range of results presented describing the distribution of answers with different likelihoods. Uncertain bad stuff doesn’t just add up. If there are 5 things that could do wrong each with a 10% chance, the chance they all go wrong is only 1 in 100,000.
Of course sometimes we are very interested even in unlikely ‘worst cases’, mainly where the outcome is disastrous and irreversible, like a nuclear power station disaster or catastrophic climate change. However, a 16 minute delay on one route for cars – whatever else you think about it – is clearly not that kind of disaster.
These sixteen minutes exist in the model. They may well never exist in the reality that the model’s seeking to predict.
The modelling doesn’t take account of lots of things that will change, if the scheme goes ahead as planned. How does the modelling work? Well, it basically takes the trips that exist now, assumes people will still keep making the same trips, and looks at how their routes may change if a particular scheme goes in. There are two linked models being used here, one a broader highways assignment model that re-routes trips across the local network, and one a micro-simulation model that looks at individual vehicle movements on shorter sections and through junctions. Figuring out changes in routes is a question of iterating the two models, using a ‘generalised cost’ equation whereby people trade off time and money to find the ‘cheapest’ (usually this means the quickest) route.
I could critique this approach, but here I’m more concerned with how it’s used. In the specific case of the cycle superhighways, there are two comparator cases, both dated to December 2016. The first is baseline plus 21 existing schemes that will affect traffic in the area, along with improvements to traffic signal management. The second also adds in the impacts of the East-West and North-South superhighways; including ‘upstream’ changes to traffic signalling to manage the movement of motor traffic outside the scheme boundaries – which generated that sixteen minutes.
But is the sixteen minutes really real? Or are we looking at a ‘worst case’ that won’t materialise? How likely is the worst case to happen? We have no idea – but there are reasons to think this worst case is pretty unlikely.
Some things in a model come with more uncertainty than others. Some variables will be associated with established estimates used for some time by that modelling group. Some won’t. The temptation – particularly if you’re trying to come up with a single figure – is to put in those things you think you know well, and leave out the others.
This can be seen as being safe and conservative but it can lead to bad decisions. The approach here is concerning because the history of transport modelling and evaluation has been so closely tied to the discredited paradigm of predicting and providing for motor traffic. This history – which we’re trying to escape from – has shaped what we count, and what we think counts. Its dead hand is still stifling London’s cycling transformation, even when we all want change. This paper by UWE (pdf) is a good introduction to the issues.
(Some of this, as an aside, is related to UK transport modelling’s focus on the trip to the exclusion of the person or the activity. This makes – mostly motorised – trips appear as sacrosanct, to the exclusion of people and the things they actually want to do.)
Uncertainty and ignorance aren’t the same thing. Even when you’re not sure the exact size of an effect, you often know something. And if you think one variable will make a key outcome increase or decrease, then assuming it has no impact (because you don’t know the exact effect size) isn’t a neutral option. If multiple factors are left out, which all affect the outcome in the same direction, you risk serious bias to the model. The best way is to include all the things, use the best estimates you can and report the range of values. You can also look at how sensitive the results are to each input variable. If you see the results are very sensitive to one input value then it pays to go away and do some more work on that one variable. By contrast there might be some variables with great uncertainty, but these actually have little impact on the final result.
In the superhighway modelling, the assumption is that motorised trip origins, times, and destinations are the same in December 2016 as they are now. Tied up with that are a whole load of other assumptions that are implausible yet hidden, because they’re ‘no change’ assumptions. I’m not even talking about mode shift here, which has been ruled out, but other factors all likely to reduce the potential for delays to motor traffic.
For example, it’s assumed that there will be no ‘peak spreading’. People who now travel in the busiest hour am and pm, will still do so. Even faced with a 16 minute longer wait for some specific journeys, the model won’t let people start arranging meetings at slightly different times, or come into work a little earlier or later.
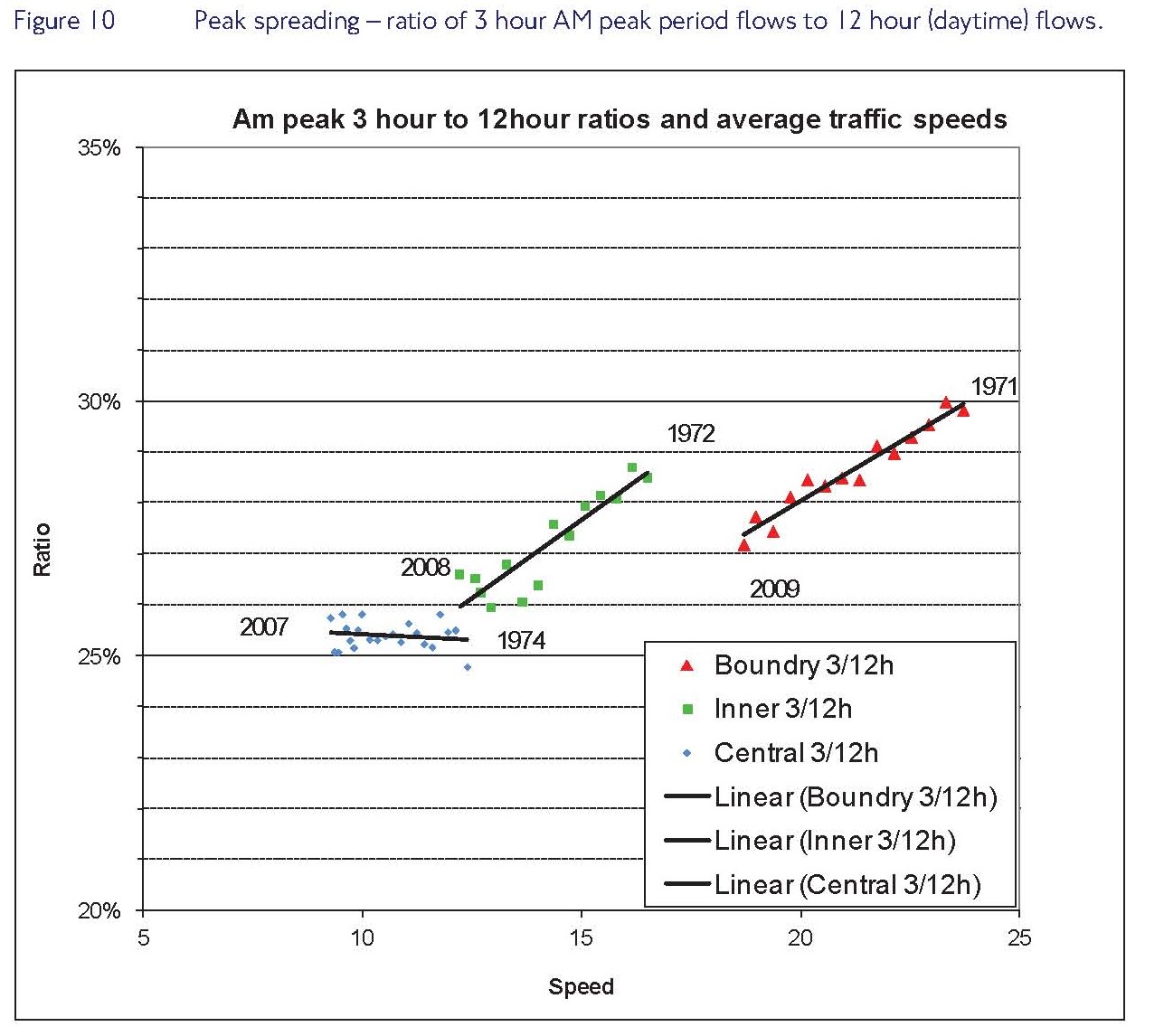
Graph from Roads Task Force technical note 2, trends and patterns for road traffic.
But that assumption’s implausible. Alongside an ongoing fall in motor traffic, we’ve seen continuing evidence of peak spreading in Inner and Outer London – the places superhighway-related delays are predicted to affect, due to ‘gating’ (rather than Central London, where off-peak journey times are also already slow). Over the past few decades, we’ve seen not just a shift away from the car in London, but also car use becoming less concentrated in that ‘problematic’ peak (the former trend in particular encouraged by the Congestion Charge, but not solely that). So the next couple of years may well see further peak spreading in any case, and potentially more of it as a response to interventions.
Another flaw in the superhighway modelling is its inability to predict cycle journey routing (where the cyclists will go, once the new routes are in operation). So one stated potential benefit is that motor traffic capacity will potentially be freed up by cyclists re-routing from nearby routes to the superhighways. But we can’t measure this reduction in potential delays, as in the model world cyclists can’t re-route.
Similarly, the model effectively posits a whole load of other relevant factors will have zero effect. TfL plans behavioural change campaigns, which WebTAG (DfT modelling guidance) says has effects that can be modelled using benchmarks. But in the model, TfL’s behaviour change campaign has precisely zero influence. In the model, enforcement’s also excluded: yet this will be stepped up and has tangible effects. A permanent police presence at the Blackwall Tunnel, supported by TfL and VOSA, has reduced delays by half.
Other interventions which here are posited to have nil effect on peak hour motor traffic include freight and servicing strategies, travel demand management, and bus mitigation measures. TfL could here be at the forefront of developing modelling parameters for these kinds of interventions. Instead, they’re not modelled, and not counted. And we end up with sixteen minutes in the model that create a major fuss, which may bear no relation to any sensible ‘worst case’ scenario, because the model effectively gives zero value to all the excellent programmes that have been developed based on TfL research and planning expertise.
In the short term, politicians and planners should hold their nerve. Sixteen minute delays, even if we are to agree they would be unacceptable, are probably very unlikely. It would be great if we knew how unlikely. But given the list of interventions and factors that will all counter the predicted delays, spending time worrying about eliminating the modelled delays will be time wasted, and could even mess up the schemes.
Crucially, in planning for worst cases, you need to think about feedback. How does your planning and mitigation affect what you’re likely to get? For example, if I assumed every official dataset was about to be withdrawn because of fraud allegations, then it’d get a lot harder to write a good project plan. I’d stop planning to use a lot of perfectly good sources.
And that’s the kind of problem I’m concerned we have here. We could make the schemes worse and worse for cycling, until we reduce a mythical sixteen minutes in the model that never would have materialised anyway. We either need to include the factors countering the sixteen minutes –with the uncertainties involved – or stop worrying about it so much.
Spurious precision from the superhighway modelling.
In the medium term, I think we need a different approach to modelling. Focusing on getting one scary set of ‘worst case’ figures is not that helpful and not really useful for policy. You get a spurious precision and not much sense of what’s actually likely to happen. We need modelling to ask more ‘what-if’ questions. Like, what if targeted enforcement at specific sites could reduce delays in a similar way to the operation at Blackwall? We don’t know exactly what might happen, but we can explore different possibilities, and contribute to refining parameters for use in future models.
Modelling should help us explore the impact of our assumptions. What are they sensitive to? What if we assumed peak spreading increased, or even reduced, rather than staying the same? What does that do to our predicted journeys and our key outcomes of interest?
Modelling can also help us think about what we might need to do to achieve a stated goal. In this case: if we’re concerned about those sixteen minutes – what level of modal shift or journey reduction would be needed to make that sixteen minutes disappear or decline to another target level? There may be complex non-linear relationships between inputs and outputs. Sometimes a small change makes a big difference. But we don’t know. If we did, it would help us think about what we need to do to get there.
More broadly, I’d like to see more openness and more scrutiny of modelling. We need academics and others to be able to play with the models, not just in relation to specific schemes, but also to ask our own ‘what-if’ questions.
There’s a lot of very complex technical work that I’m not embarrassed to say I don’t understand – but I do believe that together a range of different experts working together with modellers can help. I am pretty sure that we need a change in approach that will make the best use of the clever people and techniques that we’ve got here in London.
Does the modelling assume that traffic always flows normally or does it assume there will also be delays caused by incidents like collisions, breakdowns and the like?
If the modelling assumes no incidents but in the real world, there are incidents all the time, then I wonder what the impact is of say, a collision caused by a car driving into the back of another one and blocking a lane during the peak.
So a comparison between a worst case delay as a result of the superhighway with an incident like a collision that many would regarding as nothing out of the ordinary.
Also, the superhighways are meant to provide many benefits for pedestrians such as improved crossings. I would if it would be possible to separate out delays resulting from pedestrian improvements from those associated with the cycle lanes?
Political opponents of the scheme would be much more difficult to attack pedestrian benefits than cyclist benefits.
Yes, it’s assuming ‘normal’ traffic flow. Thanks – it’s an important point, given research shows journey time reliability is more valued by travellers than the small reductions in ‘normal’ predicted journey times that transport evaluation continues to prioritise.
And of course, cycling journey times are much more predictable than are motorised journey times, in a context like London. (One reason why it is very attractive, if conditions are right).
I’m not sure about the final point though. I’ve heard a scheme opponent arguing that if it does happen, TfL should think about maintaining motor capacity on Embankment at the expense of pedestrians!
The reliability issue is a double-edged sword in this argument. The impact of the cycle superhighway, reducing capacity for cars, may well be that the reliability of car journey times declines even more than the average journey times quoted in the Evening Standard article. Extra disbenefits, as it were, because there is less spare capacity to deal with incidents.
But the reliability of cycle journey times is probably not allowed for in modelling and cost-benefit analysis (this would first need to be measured and included in the modelling – not sure if this has been quantified in academic research?). Anecdotally and from past experience I believe jurney time reliability to be a tangible benefit of cycling for the user – which might be included in mode choice modelling (although we have generally failed to do so for other modes – also, travel time (or excess travel time, i.e. congested minus free flow) tends to be a reasonable proxy for reliability).
Excellent article, very informative, educational and investigative too – I agree, particularly, about more transparency being needed. At least that way third parties can scrutinise (spurious) results.
And maybe that way we can start / continue a real debate about what modelling is, is for and should be. In Newcastle these discussions have barely started. The city council is keeping their cards close to their chests resulting in designs ignoring cycle safety and putting motor capacity first.
This is really great analysis Rachel, thank you for taking the time to write this.
My question would be, how do we make the message of “the model doesn’t work” as short, sharp and shocking as “traffic will be delayed by 16 minutes”, without upsetting the modellers at TfL who seem to be doing their best with a system they can’t publicly admit isn’t really smart enough.
Thanks Mark. It’s a very important question.
I fear not one I’m very good at answering though being an academic (seven years of training to write longer and longer pieces comprehensible by fewer and fewer people… hence blogging as some kind of catharsis I think!)
I wonder if any cyclists working in PR might have suggestions?
I think you do a great job of presenting the (to me) seemingly unintelligible world of academia in layman’s terms!
I think you’re right, cycling does need a PR strategy of sorts. I feel a blog post coming on…
Whether the model is ‘right/accurate/realistic/useable’ is largely irreverent if you are dependent on meeting criteria to access funding. For most authorities if you fail to use the DfTs pet methods you’ve no chance, no matter how good your scheme is. TfL have more leeway than others, as they are have greater local financial control but they themselves have preferred standardised approaches. As Oscar Wilde said “‘We are each our own devil, and we make this world our hell”.
Separately most modellers will admit the failings of their work and the limitations of their models but the decision makers are only interested in the headline numbers not the long boring supporting text. This can be taken more widely as part of the BCR debate where the Strategic Case is ignored due to lazy thinking.